深度前瞻|光模块2026爆拉1.6T,中国厂商反杀海外巨头?产业新周期已至!
引言:Rubin时代开启光通信新战役
2023年以来,生成式AI热潮推动全球数据中心进入算力军备竞赛。NVIDIA为首的芯片巨头频繁升级GPU平台,AI服务器部署呈指数增长。光模块作为数据中心“神经网络”的关键器件,正面临前所未有的迭代提速。从400G、800G迅速迈向1.6T,甚至展望3.2T,光模块行业进入“T比特”时代的升级竞赛。
英伟达CEO黄仁勋近日在演讲中高呼:“Spectrum-X将在Rubin时代连接数十万个GPU ”。这一震撼宣示标志着AI算力网络架构正踏入全新阶段,也将1.6T光模块的竞赛彻底推上战场中心。Rubin平台作为英伟达2026年推出的下一代GPU与网络架构,将成为未来光模块产业演进的节奏锚点。谁能率先实现1.6T光模块的量产并匹配Rubin时代的网络需求,谁就有望在2026-2027年问鼎全球光模块龙头 。
本篇文章聚焦2025-2027年前后的全球光模块市场趋势,围绕英伟达Rubin平台升级、1.6T光模块主流技术路径、产业龙头之争、中美技术脱钩影响以及未来两年市场空间等六大方面,进行全面深入的分析,为投资者勾勒高速光模块产业的主线脉络。
在这个AI时代的光通信战场上,变局已现,率先抢占1.6T制高点者定天下 。
一、Rubin平台牵引网络架构:光模块节奏的锚点
每一代算力平台的跃迁都会重塑数据中心的网络架构。英伟达Rubin平台之所以被视为光模块产业的“节奏锚点”,正是因为它提出了前所未有的互联规模与带宽需求。Rubin GPU计划在2026年问世,与之同步亮相的还有代号“Vera”的CPU以及新一代高速互联组件——包括NVLink 6交换架构(总带宽约为 3.6 Tb/s(3 600 Gb/s,双向)),约为NVLink 5(1.8 Tb/s)的一倍和Spectrum-X系列交换机 。这些核心硬件共同构筑了Rubin时代的AI超级算力底座。与前代Blackwell平台相比,Rubin平台更新迭代将从两年一次加速为一年一更,一场超大规模AI集群的网络革命 呼之欲出。
在Rubin平台的网络设计中,有两个关键数字令人瞩目:“72”和“数十万” 。其一,单机柜内部署72颗GPU(NVLink域),通过高速铜缆实现全互联;其二,Rubin时代目标连接起“数十万”颗GPU,意味着需要将若干机柜的算力无缝拼接成一个巨型计算池。这正是光模块大显身手之处 :当计算规模从“柜内”扩展到“柜间”乃至“数据中心间”,光纤通信成为唯一可行的高速连接方式。Blackwell时代英伟达已展示了这一点——单机柜内部采用NVLink直连,但当集群扩展到多机柜时,不可避免地引入光模块连接层级。在Blackwell架构的NVL72机柜中,内部72颗GPU全部用铜缆互联,无法进一步扩展;而构建跨机柜的更大集群(如NVL576方案)时,则需要在机柜间引入光互连。数据显示,要将16个机柜(总计576颗GPU)互联成一个整体,所需的1.6T光模块数量约为GPU数量的9倍 。换言之,每增加1个GPU算力单元,约需增加9只高速光模块用于架顶交换机和层间连接。这一惊人的比例凸显了高速光模块在超大规模集群中的战略地位:没有足够密度和带宽的光模块,就无法撑起Rubin时代铺开的庞大“算力网”。
Rubin平台对网络架构的牵引作用还体现于其融合InfiniBand与以太网 的双线推进策略。英伟达正在发力AI以太网互联,其Spectrum-X系列交换机为以太网集群引入类InfiniBand的低延迟高吞吐特性。例如,Spectrum-X 800交换机 具备51.2Tb/s交换容量和200Gb/s每通道的高速SerDes,配置72个OSFP接口(支持1.6T光模块),总共可提供144个800 Gb/s 端口,同系列的 Spectrum X 1600 交换容量预计可达 ≈102.4 Tb/s,需要 1.6T 甚至 3.2T 端口配合。。这明确昭示了1.6T光模块在新一代交换系统中的核心角色——没有1.6T接口,就无法在单台交换机上同时支撑百余块GPU的吞吐需求。进一步地,英伟达计划于2025年推出Spectrum-X 800 Ultra 交换机,并在此后推出Spectrum-X 1600 系列,实现从支持10万卡互联提升到百万卡级别 集群互联的飞跃。可以想见,Spectrum-X 1600对应的是约102.4Tb/s的交换容量,唯有更高速的光接口(可能是单端口1.6T甚至3.2T)才能满足如此庞大的互联规模。Rubin平台的上线时间表,实际上为光模块行业敲定了节奏:2025年必须攻克并量产1.6T光模块,2026-2027年则要向3.2T演进 ,以匹配交换芯片从51.2T提升到102.4T、GPU集群从十万扩展到百万规模的需求。Rubin这座灯塔所投射出的时间表,成为全球光模块研发竞速的同步器——错过节奏者,将在下一轮产业洗牌中出局。
二、1.6T光模块主流技术路径:LPO、CPO、硅光之争
1.从1.6T迈向3.2T:技术演进路径与下一拐点
1.6T光模块 之所以成为当前兵家必争,正因为它是通往更高速率的关键路标。回顾以太网光模块的升级轨迹,业界通常通过提升单通道速率和增加并行通道数两种手段来提高总带宽。800G时代有两个主流方案:每通道100G共8通道,或每通道200G共4通道。进入1.6T时代,业界已趋于采用8×200G的成熟方案 ,即单通道速率提升至200Gb/s,通道数回归8路。这种方案延续了OSFP、QSFP-DD等现有封装的能力范围,在功耗和技术上相对可控。因此,1.6T并不是毫无准备的跨越——主流厂商依托7nm DSP芯片、EML高速激光器,以及成熟的PAM4调制技术,已经开发出原型产品。可以说1.6T是目前光通信产业链“看得见摸得着”的下一站,高壁垒但并非高不可攀。
然而,下一个拐点3.2T却充满未知数 。3.2T意味着带宽再翻一番,理论上有两条路径:要么维持单通道200G速率,通道数翻倍至16路;要么通道仍为8路,但单通道速率飙升至400Gb/s。第一种方案需要新封装形态去容纳16个高速光收发通道,模块尺寸和散热将面临严峻挑战;第二种方案要求业界实现224G乃至更高速率的电芯片SerDes和光器件,这涉及全新的调制格式(PAM4之后或需PAM8/16、相干技术)以及更高带宽的调制器和探测器。从目前产业趋势看,3.2T时代极可能引入革命性架构变化 ,传统可插拔方案将很难简单延伸。例如,很多专家预测单通道速率提升到224Gb/s(即每λ 400G带宽)几乎是LPO等线性驱动方案的天花板 ,在此之上模拟信号完整性变得难以保障。因此,当3.2T需求真正迫在眉睫时,光模块形态可能不得不从根本上变革,也就是业界热议的CPO(共封装光学)大概率登场接棒。这使得1.6T光模块具有某种“窗口期”意义:它可能是最后一代沿用传统可插拔形态的大容量光模块,3.2T之后规则将被改写。
值得注意的是,1.6T走向3.2T并非一蹴而就,而将经历若干过渡方案的考验。例如,有厂商提出在3.2T时代采用External Laser Source(外置激光光源)加光引擎 的模块,使激光器从模块中分离出来集中供光,以降低单模块的散热和功耗压力。这种“激光器池化”的思想可视作CPO和传统模块的折中:激光等热源外移,但调制、检测仍在可插拔模块完成。此外,薄膜铌酸锂(Lithium Niobate, LiNbO₃)高速调制器等新器件的出现,也为3.2T打开一扇窗。薄膜铌酸锂具有超宽带宽和低损耗优势,研究表明在112Gbaud以上速率,其调制性能远优于传统硅光或InP调制器。如果将薄膜铌酸锂嵌入未来的3.2T光引擎,或可在不完全依赖DSP高速补偿的情况下实现超过200Gb/s每通道的传输。这些技术储备都在为3.2T时代做铺垫。然而,不论过渡方案多么新颖,最终要验证的还是成本、良率和规模部署 。3.2T将是一次综合考验:只有在1.6T阶段积累深厚技术和量产经验的企业,才能在3.2T转折来临时立于不败。
2.LPO与CPO之争:两种路线的此消彼长
当1.6T驶入现实赛道,有两种技术路线的角力愈发凸显:线性驱动可插拔光模块(LPO) vs 共封装光学(CPO) 。这场博弈不仅关乎技术优劣,更涉及产业生态和商业路径的选择,可谓光模块领域的“路线之争”。
LPO路线 :所谓LPO,是在传统可插拔光模块基础上优化功耗的一种方案,其核心做法是去除DSP和CDR等功耗大、延时高的芯片,改用线性驱动直接处理高速信号 。传统400G/800G模块中,7nm工艺的DSP功耗常占模块总功耗的一半左右(以400G模块为例DSP约耗电4W)。DSP虽然实现了复杂的前向纠错和均衡算法,带来极低误码率,但代价是高功耗、高成本和一定的传输延迟。LPO模块通过砍掉DSP和相关重定时电路,大幅降低功耗和成本,同时减少了信号链路中的数字处理环节,降低了时延。更为关键的是,DSP芯片技术长期被少数国际大厂垄断(如Broadcom的Avago、Marvell的Inphi等),光模块厂商自研DSP壁垒极高。LPO绕开DSP,相当于绕开了一道他人把控的技术关卡,让更多厂商有机会参与高端模块竞争。2024 年 3 月,包括思科、博通、英伟达、Intel、AMD、中际旭创、新易盛、华为海思、光迅科技在内的 12 家公司联合发起 LPO MSA;2025 年 3 月(OFC 2025)成员已增至 50 余家并正式发布首版规范。他们的动机正是制定开放的线性光模块规范,打通交换机/NIC设备与LPO模块间的互操作性,推动LPO生态成熟。今年底前该联盟将发布首版标准,明年有望看到多厂家互通的LPO产品面世。这一协同行动表明业界对LPO前景的看好——在1.6T时代,LPO有望成为主流方案之一 。
当然,LPO并非没有代价。掏空DSP后,信号的损耗与畸变补偿主要依赖模拟电路和前段驱动能力,导致传输距离被限制在短距(一般 <50米)以内。这意味着LPO模块目前适用于机柜内及相邻机架连接,对于超大规模数据中心来说50米已能覆盖大部分TOR(交换机)到服务器距离,但在更长距离的汇聚层、核心层互联上LPO力有未逮。此外,LPO对电信号质量要求更高 ,当前主流112G PAM4 SerDes尚可胜任,但展望224G时代,多数业内观点认为纯线性驱动难以支撑这么高的速率。这给LPO的后续发展投下问号:如果无法突破224G电通道瓶颈,LPO或许止步于1.6T或2.0T左右的阶段,很难扩展到3.2T及以上。
CPO路线 :与LPO渐进优化思路不同,CPO走的是“颠覆式”道路。共封装光学指将光引擎直接与交换 ASIC/芯片按2.5D或3D集成在同一封装中,彻底抛弃可插拔模块和长电铜线,改用光纤把信号引出封装。这样做的最大优势就是极致的带宽密度和能效 :由于省去了芯片到模块插座的长通道和多重信号转换,CPO可以显著降低每比特传输功耗。据英伟达公布的数据,对比1.6T可插拔模块端口高达30W的功耗,1.6T CPO端口仅耗电约9W,节能幅度达70%((NVIDIA LightCounting 分析)。对于满布光口的大型交换机,这意味着数百瓦的节省,直接缓解数据中心的能耗压力。此外,CPO使高速SerDes走出芯片即进入光介质,避免了PCB走线的频率瓶颈,更容易扩展到224G、256G甚至更高速率 。业界普遍认为,当单通道速率迈向200G/400G、总速率迈向3.2T/6.4T时,CPO将展现出传统架构无法匹敌的优势。
但CPO的问题在于技术和生态尚不成熟 。首先,CPO对硅光、先进封装依赖极高,需要光电协同设计,门槛远非传统模块厂商单独能及。这导致当前能主导CPO研发的多为头部芯片巨头(如博通、英伟达)联合封装代工和光器件大厂,行业新进入者机会不多。其次,CPO的维护与互操作 是挑战:一旦把光收发固化在交换机内,设备故障时无法像更换模块那样快捷替换,而不同厂商CPO方案之间缺乏统一标准,可能形成新的技术孤岛和垄断。再者,商业模式上CPO模糊了交换设备商与光模块供应商的界限,传统供应链关系需重构,短期内各方都在观望。事实上,直到2023年以前,CPO进展一直较为缓慢,业界对于是否“现在就该上CPO”存在分歧。
英伟达在2025年GTC大会上推出了自家CPO交换机原型(InfiniBand的Quantum-X Photonics和以太网的Spectrum-X Photonics),正式吹响了CPO号角。然而值得玩味的是,黄仁勋也明确表示CPO只是可选项,英伟达仍将提供采用可插拔模块的交换机并行 。首款CPO产品会在2025年底应用于InfiniBand领域,而且据透露主要用于英伟达内部的超算集群试验;真正面向广泛数据中心市场的以太网CPO要到2026年下半年才可能推出,并且也只是Spectrum-X系列的一个“Photonic”版本,并非取代全部型号。这释放出清晰信号:在2026年前,主流市场仍将由可插拔光模块主导,CPO更多是战略卡位和技术验证 。直到2027年之后,随着博通和英伟达都计划量产200G/通道的CPO交换机,生态系统才可能逐渐成熟。由此可见,未来2-3年内,LPO和传统DSP可插拔模块仍是数据中心光互联的工作马,CPO则是远方的接力选手。
LPO与CPO之争更深层次上反映的是产业格局的博弈 。如果说CPO代表着芯片巨头和少数系统厂商主导的新体系,LPO则赋予了众多光模块企业一个延续现有游戏规则的机会窗口。在1.6T时代,由于“8×200G方案足以满足需求”,传统模块并不存在性能硬伤,加之LPO的助力,许多厂商实际并不急于全盘押注CPO。这种“技术缺位”让CPO暂难成为首选方案。而LPO阵营则在快速弥补自身短板,通过MSA联盟解决互通标准,通过改进模拟前端提升传输距离与速率。可以预见,在1.6T到3.2T的过渡期内,LPO和CPO将共存并竞争 :前者争取将可插拔模块生命周期再延续一代,后者则力图尽早证明其不可替代性。两种路线的此消彼长,最终取决于市场的选择——效率与开放生态,抑或性能与高度集成?至少在2026年前,市场更倾向于前者,而2027年以后,随着AI网络规模进一步扩大、电气互联穷途末路,后者的机会将显著增加。
3.硅光嵌入与新技术:底层创新的博弈力量
无论LPO还是CPO,要实现1.6T和更高速率,硅光子技术(Silicon Photonics)都扮演了关键但微妙的角色。所谓“嵌入地位”,指的是硅光并非以颠覆者身份单独取代传统方案,而是嵌入进各种创新架构中发挥作用。过去十余年,硅光技术一路高歌猛进:从Intel将硅光用于100G PSM4模块,到Luxtera等公司推出硅基光收发芯片,再到如今硅光成为CPO实现高密度光I/O的必然选择,可以说硅光子已融入高端光通信的血脉。但矛盾在于,硅光尚未彻底统治光模块市场 。在800G及以下速率,InP直调激光器+高速驱动的传统方案依然大量采用;而在1.6T模块中,预计有相当比例仍会使用基于InP EML激光器和直接检测的器件方案。但与此同时,硅光正以另一种方式证明自身价值:例如英伟达CPO采用了新型硅光微环调制器(MRM),Broadcom的CPO则利用硅光Mach-Zehnder调制器,把光引擎直接做到芯片封装里。这些都是传统器件无法企及的集成度。
硅光的优势在于可CMOS工艺批量制造、易于和电芯片集成 ,适合做高密度、多通道的光收发单元。从长远看,要实现像“百万GPU互联”这样规模的光网络,硅光是唯一可能支撑经济规模化的技术路线。然而当前硅光也有短板:光源问题 。硅本身不发光,需要异质集成InP激光器或通过光纤耦合外部激光,增加了复杂度和成本。此外硅光器件(如调制器、探测器)的损耗和效率在超高频下也需进一步提升。因此硅光目前更多是作为“必需的嵌入组件”而非单打独斗。例如1.6T LPO模块中,有厂商采用硅光TOSA/ROSA来实现8×200G的紧凑光学引擎,但整体方案仍结合了成熟DSP或者模拟均衡技术。再如薄膜铌酸锂调制器的兴起,则是对硅光不足的补充——在硅光微环遇到温漂和带宽瓶颈时,LN调制器提供了另一种高速选项。可以预见,在未来CPO和先进模块中,很可能出现硅光与其他光子技术“嵌套组合”的局面:比如硅光负责大部分低成本、大规模集成的功能,而铌酸锂或III-V材料器件承担最高速关键链路,以此优势互补。
从产业角度看,掌握硅光技术的话语权将成为决胜筹码之一 。美国公司在这方面起步早,Intel、IBM、Cisco(收购Luxtera)、Juniper(收购Aurrion)等都有硅光布局。硅光初创如Ayar Labs、Rockley等也得到大量资本青睐。英伟达更是直接携手台积电,利用其硅光工艺为CPO打造光引擎。不难想象,谁能提供成熟可靠的硅光子解决方案,谁就可能在3.2T及CPO时代获得产业链主导地位。中国企业也敏锐地意识到这一点:近年来国内多家厂商宣布成功研制200G/400G硅光芯片 ,如华工科技推出1.6Tb/s硅光收发芯片并在OFC上展示样片,光迅科技、海思等也积累了硅光子高速器件的自主研发能力。更有地方政府牵头建立硅光研发中试平台(如无锡的硅光互连研究院),吸引硅光创业公司落地。甚至连英伟达本身也投资了中国团队创建的硅光初创企业,可见在全球范围内硅光都是兵家必争之地。不过需要冷静的是,硅光不是灵丹妙药 :短期内它难以迅速拉低高速光模块成本,反而可能由于工艺复杂度提升带来初期高成本。对模块厂商而言,更现实的做法是“渐进式嵌入”——在哪一层出现瓶颈就将硅光用到那里,而非一蹴而就全盘替换。例如1.6T阶段,如果某个子系统(如相干驱动、光交换矩阵)需要硅光就采用,其他链路仍沿用成熟方案。这种务实策略有助于降低开发风险。总之,硅光子技术已深深嵌入未来光模块演进路线图中,但它更像一位举足轻重的盟友 而非单枪匹马的颠覆者。谁能驾驭好硅光这匹烈马,并与其他技术有效融合,谁就能在下一代光通信竞赛中占据主动。
三、谁能率先量产1.6T?龙头宝座之争愈演愈烈
800G光模块尚未大规模普及,1.6T的战鼓已然擂响。哪家厂商能够抢先实现1.6T光模块的规模量产,将直接决定其在2026-2027年的行业地位。回顾400G/800G的发展历程,每一轮速率提升都伴随行业格局的重塑。本轮1.6T竞赛同样吸引全球主要玩家倾力投入,鹿死谁手充满悬念。
业内流传着一句话:“1.6T比拼的是谁能最早接到Rubin平台的大订单,而不是谁先点亮实验室样机。” 换言之,展示原型只是入场券,真正的胜负取决于谁能拿下英伟达等核心客户的首批采购。这一点上,中国厂商被认为胜算更高——这并非偶然,中国企业在客户结构、批量交付能力、核心芯片绑定等方面具备独特优势,在北美供应链竞赛中快人一步。
从OFC展会和各家公司披露的进展看,中国厂商在1.6T研发上的动作最快,有望率先实现量产:
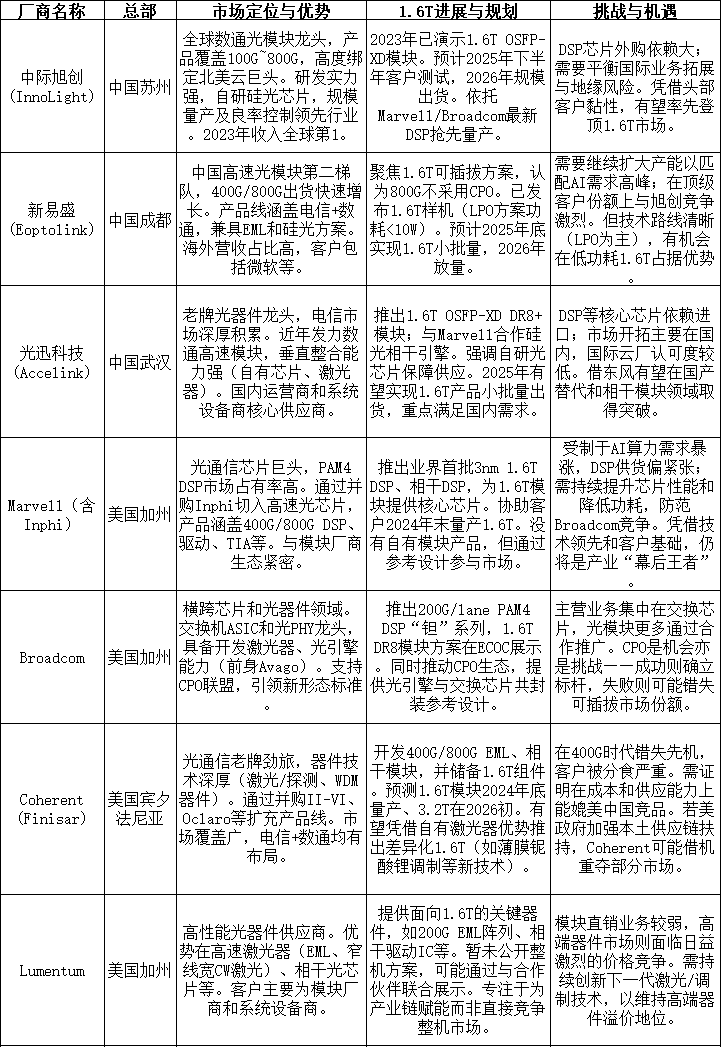
中际旭创(InnoLight) :作为全球数通光模块龙头,中际旭创早在2023年OFC上就演示了1.6T OSFP-XD DR8+可插拔模块,并展出了基于5nm DSP和先进硅光技术的第二代800G产品。公司自研的硅光芯片已在400G/800G模块中开始导入。凭借深厚的研发实力和与北美云计算巨头的紧密合作,旭创被视为最有希望第一批实现1.6T出货的厂家之一。LightCounting最新报告显示,2023年全球光模块厂商营收排名中,中际旭创位列第1,已超越美国的Coherent(原Finisar)。可见其在高端数通市场的领先地位。得益于AI算力需求的爆发,旭创顺利切入了NVIDIA等大客户供应链——2023年Q4英伟达对800G模块的巨大需求直接带动旭创当季收入暴涨。可以预期,一旦旭创在2025年推出成熟的1.6T产品,将迅速获得头部客户订单,巩固其龙头宝座。
新易盛(Eoptolink) :新易盛是国内另一家高速光模块领军企业,同样在全力冲刺1.6T。公司既精通传统EML方案,又通过全资子公司Alpine提前布局硅光技术。2024年新易盛的800G产品已在客户端批量出货,预计成为营收的重要来源。在1.6T方向,新易盛的态度十分明确:800G时代CPO不会登场,1.6T仍将以可插拔方案为主流。公司虽有CPO技术储备,但短期重心放在1.6T可插拔模块的研发量产上。根据其内部判断,1.6T产品有望在2025年下半年开始较大规模部署。新易盛预测2025年全球1.6T光模块需求量约为50~100万只,2026年将增至约500万只——如此巨大的市场蛋糕,新易盛显然不愿缺席。今年OFC上,新易盛已发布1.6T LPO模块样品,正积极送样给客户测试。凭借其出色的良率管控和大批量交付能力(这恰恰是旭创、新易盛等中国厂商的拿手好戏),新易盛完全有能力在1.6T需求起量时迅速扩充产能,跻身全球第一梯队。
光迅科技(Accelink) :作为国内老牌光器件厂商,光迅近年在数通高速模块领域厚积薄发。公司联合Marvell开发了1.6T硅光相干模块,并在硅光收发芯片、自主EML激光器等方面取得突破。光迅在2023年成功研制出1.6T OSFP-XD DR8+模块,采用16通道100G电接口和OSFP-XD封装,功耗、散热等指标达到预期,为后续量产打下基础。不过,相较旭创、新易盛,光迅的市场客户主要集中在电信运营商和国内云计算,国外超大规模客户渗透较少,短期爆发力略逊一筹。但借助完整的芯片-器件-模块垂直整合能力,光迅在1.6T时代同样有机会实现技术突围,成为国内高端光模块自主供应的重要力量。
除了中国阵营,国际厂商也在奋起直追:
Coherent(原II-VI/Finisar) :老牌美企,产品线覆盖从激光芯片到光模块。Coherent拥有强大的InP芯片实力,在开发单波长400G级别的EML和相干器件,用于1.6T及未来3.2T模块。然而Finisar在100G→400G过渡中一度丢失市场领导地位,目前市占率退居全球第二。面对更激烈的1.6T竞争,Coherent需要证明自己在成本和量产速度上的竞争力,否则可能继续被敏捷的亚洲对手超越。
Marvell :严格来说Marvell不直接销售光模块,但作为全球领先的光通信芯片供应商,它的动作极大影响着模块量产节奏。Marvell在3nm工艺上推出了“Aquila”系列1.6T PAM4 DSP,以及相干DSP“Canopus”,为模块厂商提供了核心“大脑”。据悉,Marvell的3nm DSP功耗降低超过20%,可支持8×200G PAM4信号稳定传输500米。有了这些芯片,厂商才能在2025-2026年推动1.6T模块工程化落地。因此,谁能抢先拿到并吃透新一代DSP芯片(如Marvell、Broadcom的方案),谁就能赢得量产先机。目前来看,中国头部厂商与Marvell/Broadcom联系紧密,再加上海外竞争者有限,首批1.6T量产极有可能花落旭创、新易盛等。Marvell自身则通过绑定顶级客户(如与微软、Meta在云数据中心合作),在光模块浪潮中稳固了不可或缺的地位。
Broadcom :Broadcom同样横跨通信ASIC和光芯片领域。作为交换芯片和PAM4 PHY巨头,它也具备研发高速光器件的能力(其前身Avago曾深耕激光器)。Broadcom积极推动CPO产业联盟,引领互连新形态标准。2024年ECOC大会上,Broadcom展示了200G/通道的PAM4 DSP“钽”系列(代号Sian-2),并与中际旭创、新易盛合作演示1.6T DR8光模块。这意味着采用Broadcom方案的1.6T样机已在中国厂商手中成功点亮。Broadcom还有一项独特优势:它大力倡导共封装光学(CPO)生态,其200G/波长光引擎可用于未来的CPO方案。若Broadcom成功推动CPO商业化,游戏规则可能随之改变。不过短期来看,Broadcom主要还是以芯片供应商角色赋能各模块厂商,暂不会直接参与整机竞争。
Lumentum :光器件巨头,拥有顶尖的高速激光器和调制器研发能力。Lumentum已推出面向800G/1.6T的EML阵列、相干驱动芯片等解决方案,并与国内厂商(如海信)有合作。由于Lumentum在数通光模块成品市场的占比不高,它更多以器件供应商身份出现。未来1.6T时代,Lumentum可能通过提供领先的光芯片(如窄线宽激光、薄膜铌酸锂调制器等)赋能合作伙伴,而不会大举进军整机市场。本身因为缺乏规模化模块业务,在高端器件市场又面临日益激烈的价格竞争,公司唯有持续创新下一代激光与调制技术,才能维持其高端器件的溢价地位。
综上,在1.6T竞赛中,中美日欧各路玩家同台竞逐,光模块行业正迎来新旧势力加速洗牌的关键时刻。这场竞争已超越了正常的商业博弈,更像是在大客户的联合压价下提前上演的生死淘汰赛。我们正处于产业洗牌的前夜 :谁能率先站上1.6T量产高地,谁就将改写未来几年的行业格局。
四、全球光模块主要厂商全景对比
在1.6T时代到来之际,全球光模块产业格局正发生深刻变化。传统由美日主导、华企跟随的局面被打破,取而代之的是中国厂商强势崛起,与国际巨头同台竞技的新格局。目前,中国企业凭借数通市场的成功已经在全球占据优势地位。下面我们对中美主要厂商的实力与策略进行概览:
表:全球主要光模块厂商对比(含中国与海外),资料来源:公司公告、公开研报等
_ _
由上述对比可见,在AI数据中心高速光模块这一细分领域,中国厂商已全面领先:无论产能规模、客户关系还是产品迭代速度都占据优势地位。这与五年前截然不同——2018年前后,全球100G/200G模块市场还是Finisar、Lumentum、Oclaro等美企唱主角;但到了800G时代,中际旭创、新易盛的出货量已经比肩甚至超过了老牌对手。而1.6T则可能成为中国厂商建立绝对领先优势的历史性窗口期。
当然,海外厂商也并非束手就擒:他们深耕光芯片和前沿技术,或许无法在成本上与中国制造匹敌,但在高端技术和本土市场上仍有壁垒。例如,美国云计算巨头出于供应链安全考虑,可能扶持本土或盟国供应商,以免关键领域完全受制于人。因此,未来的格局很可能是“中美双雄”并存:中方厂商占领全球主要份额,美方少数企业守住高端和特定客户市场。对于投资者而言,需要密切关注技术演进和政策环境对各家企业的影响,动态评估其竞争力消长。
五、中美脱钩下的突围:中国光模块能否掌握1.6T时代主导权?
一个不容忽视的背景是:中美科技博弈正愈演愈烈。继半导体、AI芯片之后,光通信也成为可能的角力场。高速光模块涉及高速ADC/DSP芯片、激光器等关键器件,美国如果祭出出口管制,中国企业是否具备技术突围能力,将直接影响其在1.6T时代的话语权。
目前来看,中国在光模块整机集成和制造方面优势明显,但在核心上游仍有短板:
高速DSP芯片 :这是决定800G/1.6T性能的“大脑”。当前全球PAM4 DSP几乎被美企垄断(Marvell、Broadcom、MaxLinear等),国内尚无可商用的800G/1.6T DSP,仅个别初创公司宣布了研发进展,但与国际巨头仍有明显差距。如果美国对DSP芯片实施出口限制,中国厂商将立刻受制于人。事实也证明了这一点:在近期800G需求爆发下,国内厂商因DSP供给不足一度出现供不应求的情况。好在目前尚无迹象显示美国会限制光通信芯片出口,再加上中国厂商也是美国云巨头的重要供应商,短期风险不大。但长远看,发展自主高速DSP势在必行。可以预见,国内科研力量(如烽火通信、中科院系初创企业等)将加大在100G PAM4、相干DSP上的投入,有望取得一定突破,从而逐步降低对美方的绝对依赖。
激光器与高速调制器 :过去高速EML激光芯片长期依赖美日厂商(如Lumentum、住友电工等)。近年国内厂商通过并购整合,在25G DFB、100G EML芯片上取得长足进步。例如光迅科技、华工正源等相继推出自研100G EML激光器芯片并实现量产;索尔思光电(Source Photonics)更宣称其光芯片自给率达90%。可以说,在光芯片(不含DSP)环节,中国已打下相当基础。1.6T时代的新挑战在于实现单波长200G的激光与调制技术,这涉及多波长集成、薄膜铌酸锂调制器等前沿方向;量子点激光(QD Laser)亦具潜力,但尚处研发初期,距离规模商用仍有距离。值得庆幸的是,在这些前沿领域,中外几乎站在同一起跑线。如果中国企业加大研发投入,有机会弯道超车,形成差异化竞争优势。
材料与设备 :光模块生产还涉及精密封装、光纤耦合设备等领域。这方面中国已深耕二十余年,自动化水平和良率并不逊色于国外。同时,“脱钩”压力激发了国内供应链的协同,加速推进高速驱动芯片、TIA放大器等进口器件的替代。整体而言,中国光模块产业链较为完整,具备相当韧性来抵御外部冲击。
除了自身技术储备,在国际市场环境下,中国企业还有两张王牌可以打:成本效率 和市场规模 。前者指中国制造在规模化生产上的成本优势——即便暂时缺乏最新一代DSP,也能通过更高集成度、优化设计,在满足性能需求的前提下以更具性价比的产品赢得客户;后者指中国本土及新兴市场的巨大需求,即使失去部分美系订单,国内“东数西算”等工程也能支撑起可观的销量。因此,即便发生最极端的脱钩情景,中国光模块厂商也绝不会无路可走,完全有可能另起炉灶建立自主生态,尽管短期内产品性能可能落后半代。
需要看到,中美在光通信领域尚未走向彻底对抗。相反,在AI浪潮下双方产业高度共生:美国云公司离不开中国提供的大批低成本高速模块,中国厂商也需要美企芯片来打造顶尖产品。这种互补关系降低了完全脱钩的可能性。近期中美高层互动增多,美国还暂时豁免了光模块加征关税,释放出缓和信号。因此更现实的情况是——中国厂商继续主导中低成本的大批量市场,美企维持高端器件/芯片供应,两者在竞争中合作,共同推动技术演进。中国企业则应趁势练好内功,逐步补齐芯片短板,构筑从芯片到模块的完整自主能力,这样无论外部风吹草动,都能做到泰然应对。
总之,在1.6T时代,中国光模块企业有望延续近年的突围态势,甚至实现产业格局的反超。但必须清醒认识到,上游核心技术的欠缺依然是一把高悬头顶的达摩克利斯之剑。唯有加强产学研协同、自主创新,才能将外部变量转化为自我跃迁的契机,在全球光通信版图中赢得更大的战略主动。
六、未来两年展望:市场规模、AI服务器与价格走势
展望2026年,高速光模块市场将在AI基础设施投资浪潮下保持高速增长。多方研究预计未来两年全球光模块市场规模将维持20-30%的年增速。尤其AI训练集群对800G/1.6T模块的爆发性需求,将使数通光模块成为行业增长的主引擎。
据LightCounting和Yole的预测数据:全球光模块市场到2028年达到约223亿美元,主要由中国供应商和节能型AI光模块驱动。其中AI用途的高速模块部分增长最迅猛,预计年复合增速高达47%。换言之,未来五年AI相关光模块市场规模有望扩大数倍,在整个光模块版图中的占比迅速提升。Yole进一步估计,仅2024年一年,AI驱动的光模块销量就将同比增长45%。这与当前全球云巨头的资本开支动向高度吻合:微软、Meta、亚马逊、谷歌等在2024年均大幅提高针对AI数据中心的投入,为光模块需求提供了强劲动能。
从AI服务器出货量看,同样是大幅跃升。TrendForce数据显示,2024年全球AI服务器出货量同比增长约46%,2025年在高基数上继续增长接近28%。这意味着大量配套的高速互连模块需要同步部署。一台典型AI训练服务器通常搭载8张GPU,每张GPU配备多条高速光链路(如InfiniBand或以太网NIC)。有测算称,一个包含数千GPU的大型AI集群需要数万只400G/800G模块来互联,光模块成本已占据整体基础设施成本中相当可观的比例。英伟达等供应商也在产品路线中直接指出:未来Blackwell GPU搭配ConnectX-8网络时,将极大推升对1.6T模块的需求。可以预见,2025年AI训练集群的大规模建设,将使800G模块需求持续超预期增长;而2026年起1.6T模块也将开始批量部署,由此撑起整个行业新一轮的景气周期。
资本开支方面,云巨头已经释放出明确信号:2023年下半年起显著加码AI相关投资。以谷歌为例,2023年上半年资本开支132亿美元,下半年起将继续聚焦AI基础设施;微软2023财年Q2(对应自然季度2023Q4)单季资本开支高达89.4亿美元,同比大增,主要用于服务器、网络设备和数据中心升级;Meta则宣布未来几年投入数千亿美元建设AIDC(AI数据中心)。这些投资有相当大比例将流向网络互联设备,包括交换机与光模块等。行业测算显示,在传统数据中心中,网络设备约占总成本的10-15%,但在AI超算中心,这一比例上升到20-25%——因为高速互连的重要性显著提升。换言之,在AI时代每投入1美元算力,约需同期增加0.2美元的高速通信投入。这使得光模块厂商将显著受益于AI资本开支周期,其收入弹性甚至可能高于服务器厂商本身。
随着产品迭代和规模量产,光模块单位带宽成本总体呈下降趋势。以最近两代产品为例:400G模块单价曾高达$1,000以上,如今已降至约$250;800G模块目前售价$600-900不等。尽管800G模块绝对价格高于400G,但摊到每Gb/s带宽,成本反而更低(带宽成本约为400G的一半)。这一“成本/比特”下降趋势在1.6T时代将延续。预计初期1.6T模块单价可能在$1,200-1,500区间,虽然绝对价格高于800G,但单位带宽成本可比800G再降低约20-30%,延续代际成本递减规律。特别是LPO技术的引入,有望进一步改善模块成本结构:去除DSP后新增的高线性度Driver/TIA成本远低于DSP价格,使整体成本下降,同时功耗降低带来的运维节省也不可忽视。你以为这只是降价信号?其实这是硅光封装等技术达到量产临界点的明证。
需要指出的是,短期内价格仍受供需影响。自2023年以来,800G模块一度供不应求,甚至出现提价和交期延长的现象。正所谓“风浪越大鱼越贵”,在技术难度和产能瓶颈尚未完全突破前,高端光模块的毛利率不降反升——龙头公司由此赚取了可观超额利润。待产能爬坡、更多竞争者加入后,价格才会回归正常轨道。由此推断:2025年800G模块价格将保持坚挺,降幅有限,以保证供应链有足够动力扩产满足AI热潮;到了2025年底,随着1.6T产品逐步问世、800G供给改善,800G价格可能出现较明显的下调,而1.6T新品由于竞品少、初期产能有限,仍将维持高位。2026年以后,1.6T进入规模出货阶段,多家量产形成竞争,届时1.6T价格将快速走低,逐渐趋近大众化水平。总的来说,高速光模块行业遵循典型的周期性降价规律:以400G和800G为例,产品问世初期价格高企,毛利率超过50%,但随产能提升、技术成熟,2-3年内价格会下降40-60%;厂商则依靠出货规模的飙升来保持整体盈利稳定。
值得关注的还有产品组合的变化。未来两年,400G在传统数据中心仍有大量需求但增速放缓;800G成为旗舰产品并逐步向下渗透,中低端市场(二线互联网厂商、企业级用户等)也开始批量导入800G模块升级骨干网;而1.6T则作为超高端产品小批量上柜,主要供应AI集群等顶级算力中心。由此,各厂商的收入结构和利润率将受产品组合影响:高端产品占比越高,平均售价和毛利越可观。例如2023年中际旭创因800G占比提升,综合毛利率显著上扬;到2025年,谁能率先将1.6T占比提上去,谁的业绩表现就可能进一步优于同行。这也为投资者研判企业盈利趋势提供了一个切入点。
结语:抢占1.6T制高点者定天下
“风起于青萍之末,浪成于微澜之间。”当下1.6T光模块正处在由量变引发质变的前夜,其意义已远超一款产品本身,而是关乎未来数年光通信产业格局的重塑。本文通过结构化的分析和数据论证,可以清晰地看到这样一个结论:率先实现1.6T光模块规模量产并绑定Rubin时代AI网络需求的厂商,将大概率主导2026-2027年的全球光模块格局 。这一论断源自多方面逻辑——Rubin平台对高带宽互联的迫切牵引、1.6T作为技术演进必经的关键节点、LPO/CPO路线博弈延缓了范式切换、以及巨量市场需求下“赢者通吃”的规模效应。抢先一步踏上1.6T征程的企业,不仅能够赢得当前订单和营收,更将在品牌认知、客户黏性和经验曲线方面建立起难以撼动的护城河。
反之,未能跟上1.6T节奏者,即便背景再雄厚,也可能在这一轮浪潮中被拍倒在沙滩上。两年时间转瞬即逝,留给后来者的机会之窗将极其狭窄。尤其是在AI驱动的光模块大战中,速度就是生命,规模就是胜负手 。拥有明确战略和执行力的公司,正夜以继日攻关技术、扩充产能、深挖供应链,只为在Rubin平台全面铺开之前卡位占领制高点。当硅光、DSP、工艺、生态各路资源在赢家周围加速聚集时,马太效应将愈发明显——强者恒强,领先一个身位就意味着领先一个时代。
历史经验表明,每一次通讯速率的飞跃都会改写行业座次。从10G到100G、100G到400G莫不如是。而这一次,从800G跨越到1.6T,甚至预示着向3.2T、6.4T迈进的起点,更是关系未来五到十年产业版图的战略制高点。我们明确主张:1.6T之争不只是技术指标的较量,更是战略洞见和产业格局的比拼 。光通信战场上没有“稳妥”的守成者,只有敢于押注未来的开拓者。站在2025年这个时间节点,AI大模型的炽热浪潮已经将光通信行业烧出了新的形态:东西方厂商同场竞速、新旧路线殊途同归,机遇与风险并存。综合本篇分析,我们可以自信地说:1.6T光模块之战,已见硝烟;胜负悬念,则将在未来两年内见分晓 。让我们拭目以待,谁将成为这个光速时代的新王者。