深度剖析:DeepSeek的崛起与挑战,AI模型价格战背后的技术博弈
自2025年初DeepSeek推出其旗舰模型R1以来,仅半年光景,就搅动了整个AI产业的池水。这不仅是一场简单的新品发布,而是一场赤裸裸的“价格屠杀”和国产反击战。作为首个公开发布的、在中英文通用性与推理能力上接近OpenAI o1的国产大模型,DeepSeek R1以极具侵略性的定价策略——输入仅0.55美元/百万Token,输出仅2.19美元/百万Token ,在全球AI市场引发强烈震动。这一价格远低于行业主流水平,令众多巨头陷入哑然失声的尴尬境地,也迅速将整个AI模型赛道拖入了价格内卷的深渊。
然而,当掌声逐渐消退时,质疑声便不可避免地浮出水面。DeepSeek的低价策略背后隐藏着明显的运营瓶颈和技术挑战。从平台流量来看,Web端访问量并未持续攀升,用户的转化率和留存率也持续承压,凸显出价格战无法长期维系用户黏性的现实。在用户体验和系统稳定性方面,DeepSeek虽然面临与高端模型同样的期待值,却未能在交付水平上同步跟进。
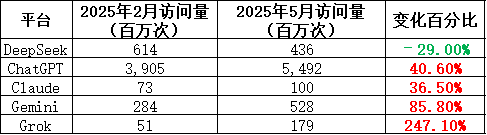
从平台活跃度的角度来看,DeepSeek的整体表现更像是一场高开低走的营销实验。尽管第三方平台的API调用量快速攀升,但其自有平台的用户增长却明显乏力。这种“热度外溢、内场冷淡”的现象揭示出一个残酷的现实:价格固然能吸引初始用户,但在服务质量、响应速度及任务完成度这些硬指标上,却无法真正构筑起竞争壁垒。
在AI模型的运营体系中,Token早已成为计费与处理的核心单位。一个Token往往代表一串字符或符号,是模型最基础的计算颗粒。
DeepSeek选择以低价抢占市场,但成本压力并未因这种理想主义而消失。为了控制支出,R1模型并未在响应延迟和吞吐性能上追求极致表现,导致高负载场景下响应速度略显迟缓。此外,DeepSeek的上下文窗口设定为64K Token,虽满足大部分日常任务,但在长文档及复杂代码处理场景下,却不及竞争对手提供的128K配置,形成了其通用性上的隐性瓶颈。
资源压力绝非DeepSeek一家的难题。在全球范围内,AI厂商集体进入了“算力瓶颈时代”。Anthropic的Claude Code模型虽然在代码生成和审校方面取得惊人成效,但其团队也坦承,模型在处理多轮复杂推理任务时,正被底层硬件吞吐能力拖累。当前的AI竞争早已从架构设计阶段转移到了对GPU调度能力及能效比的军备竞赛阶段。
与此同时,行业正快速转向“Token即服务”(TaaS)的新型计费模式。这种计费方式更贴合模型调用的真实成本结构,更利于云端弹性算力的灵活调配。DeepSeek紧跟这一趋势,将R1模型开源,并通过Hugging Face等平台进行部署与下载。其竞争对手Anthropic、Mistral等公司则已与AWS、Google Cloud等云巨头达成深度绑定,以期在资源弹性上抢占先机。这是一场毫无退路的资源战争。
价格与性能之外,安全性问题同样不可忽视。2025年上半年公布的一项研究指出,DeepSeek R1模型在中文提示词注入攻击(Prompt Injection)场景下,攻击成功率接近100%。这不仅为其在政务、医疗、金融等高敏感领域的应用前景蒙上阴影,更凸显了模型对齐性和安全性问题,已成为AI模型能否进入核心应用场景的基本门槛。
更具争议的是其训练成本的透明度。DeepSeek声称仅用数百万美元的算力资源完成了R1的训练,但包括OpenAI CEO Sam Altman在内的多位行业领袖对此提出质疑,认为若没有数千块GPU的支持,很难达到如此性能。这场“成本悬案”至今未定,暴露出AI产业信息不对称及估值虚高的系统性风险。
对投资者而言,AI模型的未来取决于“资源调度”、“定价逻辑”、“安全壁垒”以及“行业融合”四个关键维度。未来能够长期立足的公司,必须解决三大核心矛盾:一是牢牢掌控算力基础设施,包括GPU硬件与调度系统;二是在基于Token经济的商业模式设计中,以更高的Token效率换取更低的调用成本,从而主导新一轮计费体系;三是实现模型能力向垂直行业的深度渗透,真正超越简单的对话工具,兑现复杂场景中的商业价值。
DeepSeek的故事告诉我们,靠“性价比”只能短暂吸睛,若要长期留存用户,必须依靠稳定性、专业化及生态整合的综合实力。这并非一场靠价格就能取胜的游戏,而是一场系统级能力的全面较量。
未来3到5年,AI行业将进入更为残酷的深水区——参数规模与推理速度的单一指标将不再是核心卖点。取而代之的将是多维指标的组合竞争,包括资源效率、安全机制、计费策略、垂直应用能力,以及模型的开放性与生态整合能力。最终生存下来的,不是最炫酷的技术,而是最能跑通商业模式、最懂产业协同的玩家。
对于DeepSeek而言,从性价比时代迈入基础设施时代,这条升级之路才刚刚开始。未来能否不仅成为“国产之光”,更能成为全球AI版图上的关键节点,仍需市场和时间的检验。