英伟达Blackwell和Rubin,差别到底在哪?
在人工智能算力需求爆炸式增长的时代,英伟达(NVIDIA)持续引领芯片技术革新。2024年推出的Blackwell芯片已成为AI训练与推理的核心算力引擎,而2025年GTC大会上亮相的Rubin芯片,则预示着下一代AI基础设施的演进方向。本文将从性能、价格、市场前景、上下游影响及未来发展五个维度,分析这两款芯片的差异。
一、性能对比:从Blackwell到Rubin的算力跃迁
Blackwell芯片性能概览
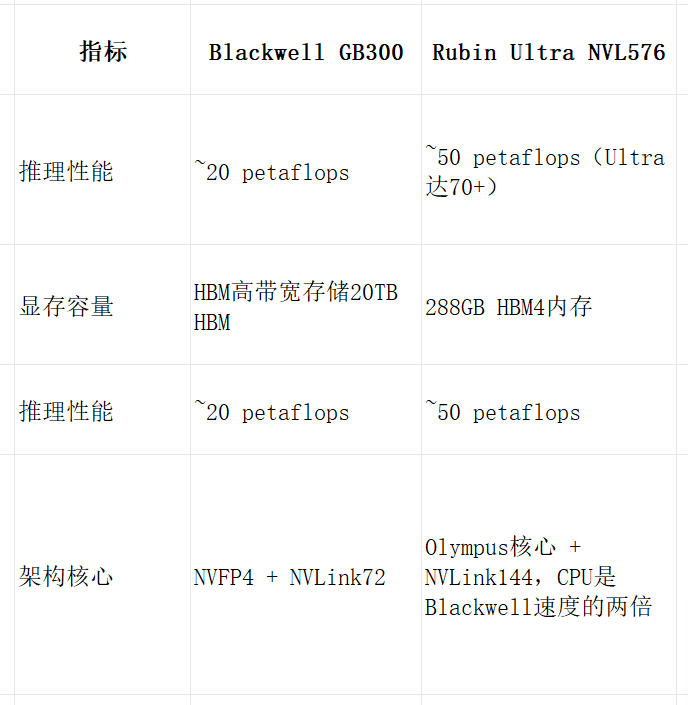
Blackwell芯片(如GB200、GB300)采用NVLink72互联架构,支持高达20TB的HBM存储,推理性能比前代Hopper提升11倍。其NVFP4精度优化使每token能效提升50倍,尤其适用于大模型推理场景。功耗方面,GB300达到1400W,需配备冷板水冷系统。
Rubin芯片性能亮点
Rubin芯片则是英伟达首次将CPU与GPU进行3D封装集成,采用Olympus核心架构,推理性能达50 petaflops,是Blackwell的两倍以上。其HBM4显存高达288GB,支持NVLink144互联,Rubin Ultra版本性能更是GB300的14倍,为未来AI模型的千亿参数级推理提供保障。
性能总结对比表(仅供参考)
二、市场前景与上下游带动
下游:
Blackwell正在成为英伟达明年AI业务的主要支柱。Blackwell芯片发布后,微软、谷歌、亚马逊等科技巨头已订购超360万颗芯片。根据黄仁勋自己所言,2025年AI在中国的商机预计就会有500亿美元,未来几年增长率达50%。Blackwell推动AI推理从实验室走向大规模商用。
Rubin芯片预计2026年量产,优先供应大型云服务商。Rubin Ultra NVL576将于2027年推出。英伟达预计未来十年AI基础设施支出将达3–4万亿美元,Rubin将成为核心算力支柱。
上游:
光模块:随着Rubin芯片的出现(以及今后的Feynman),其对光模块性能的要求也会指数级增高。新的3.2T,乃至6.4T光模块将进一步挑战电光学瓶颈,进而为更先进的技术——硅光子技术的出现提供了舞台。
液冷:目前显卡单卡功耗已进入千瓦级,传统风冷彻底失效。液冷成为主流解法。AI大模型训练与推理的高功耗场景,迫使数据中心必须全面采用液冷架构。液冷的重要性不仅体现在散热本身,还在于它是AI基础设施升级的必经路径。光模块带来高速传输,液冷保障稳定运行,二者共同构成AI算力扩容的底层支撑。与此同时,液冷的普及也带动了AI散热材料与模组的系统性机会。热管理组件、石墨烯导热片、复合材料的应用正在快速推进,为AI服务器提供更高效的散热解决方案。
AI交换机:GPU算力的提升,最终会将系统瓶颈转移到数据传输上。AI交换机就是数据流量的中枢。随着NVLink等高速互联架构的升级,交换机的重要性被不断强化。未来的
AI交换机将沿着,集群扩张 → 传输瓶颈 → 高速交换机的方向爆发。
AI服务器与整机柜方案:Blackwell时代的NVLink已把72块GPU互联在一个机柜内,功耗飙升至千瓦级。Rubin时代将更进一步,将扩展到至少144块GPU互联。
三、未来发展趋势与战略意义
技术演进路径
Blackwell代表AI推理的商业化阶段,而Rubin则开启AI算力的“融合时代”,CPU与GPU集成、液冷系统普及、HBM4显存应用等技术将成为新常态。
英伟达通过Blackwell实现AI芯片的规模化部署,通过Rubin则构建未来AI基础设施的核心。其芯片路线图(Blackwell → Rubin → Rubin Ultra)清晰展现了对AI算力演进的掌控力。
Rubin芯片的高性能与高成本将推动AI基础设施升级,但也对电力、冷却、供应链提出挑战。行业需同步发展液冷技术、绿色算力方案与芯片制造能力,以支撑Rubin时代的到来。
结语
英伟达Blackwell与Rubin芯片的迭代,不仅是技术参数的跃升,更是AI产业生态的重构。从Blackwell的推理能效革命,到Rubin的融合算力突破,英伟达正引领AI芯片迈向更高维度。未来,随着Rubin芯片的量产与部署,AI算力将进入“千亿参数模型”时代,推动人类与智能的深度融合。