博通的算盘:携手OpenAI造芯,能否撬动英伟达?
近日,博通CEO陈福阳(Hock Tan)在财报电话会上透露,公司新增了一家AI领域“大客户”,获得其超100亿美元的AI基础设施订单,但未具名客户身份。多方消息源证实,这一神秘新客户正是OpenAI。据悉,该订单将在2026财年开始贡献营收,博通将为OpenAI定制研发AI加速芯片并提供后续硬件交付。
此举被视为OpenAI为缓解算力供给和成本压力而开启的“造船”计划,但短期内仍难撼动英伟达(Nvidia)的主导地位——决定胜负的关键不在单颗芯片性能,而是生态体系、系统级交付能力和开发者锁定等综合优势。
一、博通和 OpenAI 百亿订单背后的“算计”
OpenAI押注自研芯片,背后是其算力需求和成本飙升的巨大压力。内部预测显示,OpenAI已将2025年至2029年的累计现金消耗预期大幅上调至约1150亿美元,比之前预期高出800亿美元。作为当今全球最“烧钱”的创业公司之一,OpenAI面临前所未有的资本开支挑战。
为了控制飙升的算力开支,OpenAI计划开发自有的数据中心级AI芯片并建设配套设施,以降低对外部GPU云资源的依赖。今年7月,OpenAI深化了与Oracle的合作,规划建设4.5GW的数据中心集群;其“Stargate”项目甚至设想投资高达5000亿美元、建设10GW算力,由软银等提供资金支持。这些举措表明,OpenAI正从芯片设计到数据中心基础设施,全面布局上游供应链,以“自己造船”的方式保障未来算力供给和降低单位算力成本。
对于博通而言,与OpenAI的定制芯片合作不仅仅是笔大订单,更代表着新的战略增长曲线。博通过去凭借面向苹果等大客户的定制芯片(如无线射频组件)奠定了稳健业务,如今希望将这一模式复制到AI时代,即通过“定制硅+机柜级硬件”服务超大客户,获取高确定性的长期收入。此次与OpenAI签订的百亿美元级合作,无疑为博通打开了AI定制芯片业务的增量空间。订单一旦规模化量产,博通可在较长周期内锁定可观的现金流和毛利率,大幅提升业绩稳定性。
陈福阳就此表示,新客户带来了“立竿见影且相当可观的需求”,将使2026财年AI业务展望“显著改善”。博通股价在消息公布后大涨,反映市场对其押注AI定制芯片前景的看好。可以说,这份来自OpenAI的超级订单,对博通意义重大:一方面巩固其在AI基础设施供应链中的地位,另一方面验证了“为头部玩家打造定制算力方案”这一模式的可行性。这将成为博通继传统通信芯片、企业软件之后的第二增长引擎,为公司未来业绩提供强劲支撑。
二、AI 巨头+芯片公司的新合作模式
近年来,科技巨头与半导体公司合作开发AI芯片的模式渐成常态。其基本商业逻辑是:由客户提出需求和资金支持(包括一次性研发费用NRE) ,芯片公司负责定制ASIC/加速器的设计量产 ,并进一步提供机柜级硬件配套 (例如交换芯片、存储控制、互连网络等)来构建完整解决方案。这种模式下,芯片公司深入绑定客户需求,为其量身打造硬件,加之提供整套基础设施方案,显著提高了客户锁定度和对规格标准的影响力。对于客户而言,虽然需承担前期NRE投入,但换来的是更优的性价比和供应保障;对于供应商而言,一旦合作达成,大批量订单带来规模效应,利润率和营收的可见度也更高。
正因如此,谷歌、亚马逊、Meta等公司近年来纷纷投入自研或合作开发AI芯片,以摆脱对第三方GPU的完全依赖。OpenAI此次选择与博通联手,正是延续这一潮流:由博通提供定制“XPU”加速器(博通对定制AI芯片的称谓)并整合到整机柜系统内,专供OpenAI庞大的模型训练和推理集群使用。
需要强调的是,无论是谷歌TPU还是OpenAI定制芯片,其制造和封装仍高度依赖台积电等晶圆代工和先进封装生态。尖端AI芯片往往采用台积电5nm、3nm工艺,并使用CoWoS等2.5D封装技术将HBM高带宽存储集成,这些都不是芯片设计公司自身可以完成的。
OpenAI早在2024年就曾与台积电合作,为其首款自研芯片进行流片准备。这意味着,即便自研芯片,在产能保障上仍需与其他客户争夺代工资源。
目前英伟达已经提前锁定了台积电相当比例的先进产能和CoWoS封装能力(据报道其2025年CoWoS封装产能占有率超过70%),新进入者要获取足够产能并非易事。
不过,博通在供应链组织和客户项目执行方面久经考验。作为一家“整合型芯片巨头”, 博通擅长将大客户的定制化需求落地为硅片和系统产品,并确保按时可靠交付。这种能力源于其多年服务超大客户的经验——无论是苹果手机的无线芯片,还是云计算厂商的定制ASIC,博通一直以交付稳定著称。
陈福阳强调,与超大规模客户联合开发专用加速器是一段需要软硬件协同演进的“旅程”,需要双方多轮迭代,不断让算法与硅片深度结合优化,才能在性能上达到第三方通用芯片无法企及的高度。这种端到端的合作模式并非一般芯片设计初创公司所能承接,反而是博通此类有丰富产品线和供应链掌控力的公司之独特强项。
从资本市场和行业格局看,大客户定制芯片浪潮对AI芯片产业的影响是结构性的而非颠覆性的。博通拿下百亿美元订单,意味着其AI定制硅业务在未来几年收入高增确定性强,这已反映在乐观的财测指引中。一些分析师预计2026年博通定制AI芯片业务增速将远超英伟达同期芯片业务增速。
然而,需要注意的是,这类定制芯片通常“只服务于单一客户内部”,并不参与开放市场竞争,也不直接输出到更广泛的生态中。因此,对整个行业竞争格局的撼动相对有限。以谷歌TPU为例,虽然性能出色,但主要部署在谷歌自家数据中心(或Google Cloud供客户使用),并未取代英伟达GPU在行业内的通用地位。
OpenAI的芯片也是类似——只在OpenAI/微软内部使用,不会出售给其他公司。这意味着英伟达面对的外部客户需求并不会因为OpenAI自研芯片而急剧减少,充其量是少了一个直接采购GPU的大户。但考虑到OpenAI背后微软Azure仍会采购大量英伟达GPU提供云服务,以及其他成千上万的AI初创公司和企业客户仍以英伟达为首选,加上OpenAI芯片本身性能和适配情况未知,短期内行业版图不会因为这一单合作而改写。
概言之,巨头自研芯片更多是为自身降本增效,并非马上颠覆供应格局 。英伟达在GPU市场的复合优势,仍使其成为大多数AI落地场景的首选方案。
三、英伟达为何难以被打败
表面看来,AI芯片之争是算力峰值的比拼,然而更深层次的护城河来自软硬件生态的厚度 以及系统级交付能力 。英伟达之所以难以被撼动,正是因为其构建了一个从芯片到软件、从单机到集群的闭环生态体系 ,远非一两代“更快芯片”所能替代。这其中,英伟达掌控的几个整个产业的以下几个关键节点:
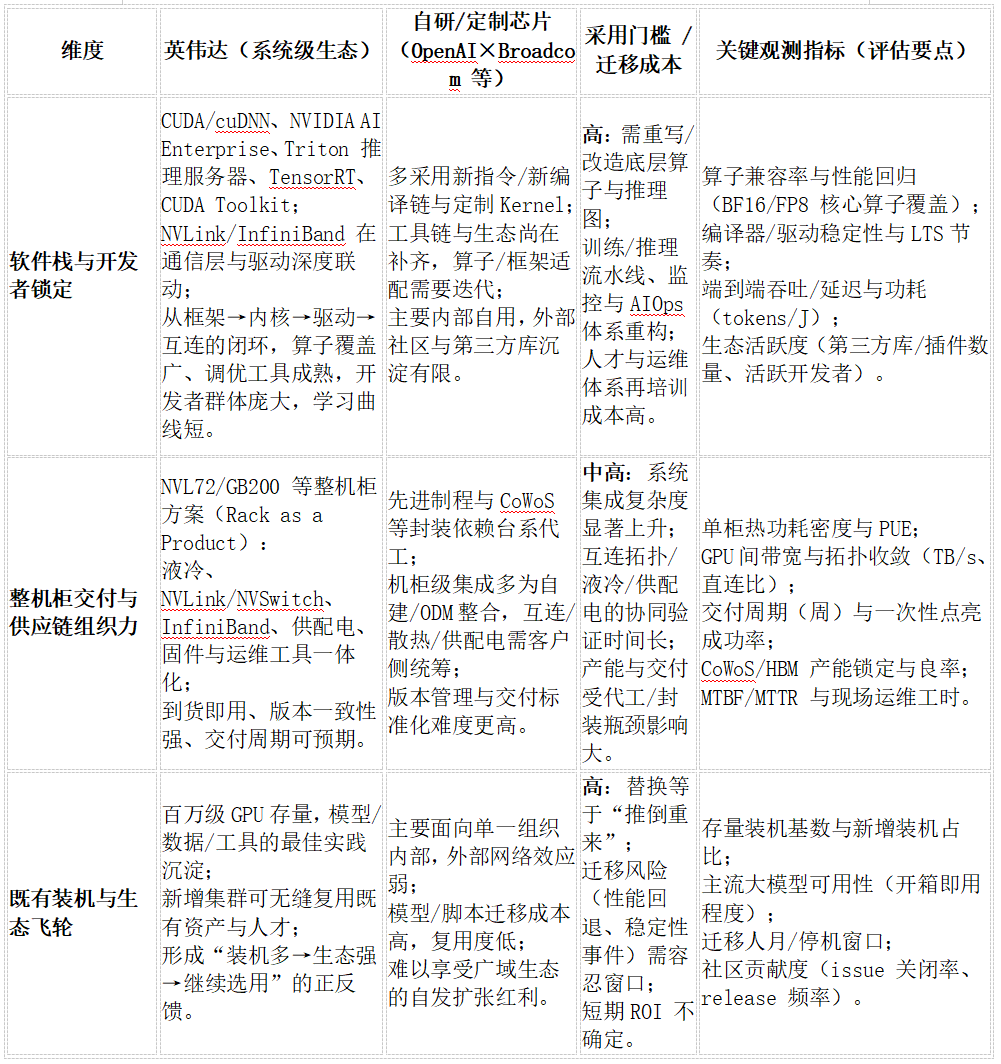
1.软硬件栈与开发者锁定 :英伟达经过多年投入,打造了CUDA为核心的完整软件栈。包括深度学习框架配套的cuDNN库、加速计算的TensorRT推理优化器、企业版的NVIDIA AI Enterprise套件、提供分布式训练推理的Triton推理服务器,以及底层的NVCC编译器和驱动支持等。
这套体系几乎无缝衔接了从模型框架到GPU指令的各层级,使开发者可以方便地在英伟达GPU上开发、优化和部署AI模型。长期下来,CUDA已成为AI研发的工业标准,大部分AI模型的训练代码、工具链都深度绑定于此。
“站在巨人的肩膀上”使得新模型的开发变得高效而可靠,但代价是开发者被牢牢锁定在英伟达生态内。若要迁移到其他芯片架构,往往需要重写底层代码或等待相应兼容层的成熟,成本高昂且风险巨大。
正因如此,新晋AI芯片想撬动这一局面,除非在性能或效率上提升一个数量级(2-10倍) ,否则很难令用户放弃成熟工具链而投入额外成本适配。换言之,英伟达的软件生态本身已成为强大的护城河 ,竞争对手不仅要造出硬件,还得补齐整个软硬件协同体系。
这也是OpenAI自研芯片仅供内部使用的局限所在:它并不会自动诞生出一个类似CUDA的公共生态,无法吸引外部社区共同完善工具链和应用适配,难以形成正反馈的网络效应。
2.整机柜交付与系统整合 :在硬件层面,英伟达同样建立了系统级解决方案 的壁垒。如今顶级AI集群的部署,远非采购芯片那么简单,而是需要考虑通信带宽、存储IO、供电散热、集群管理等诸多因素。英伟达通过推出预集成的整机柜产品(如DGX SuperPOD、MGX模块化服务器,以及最新发布的GB200 NVL72整柜方案等),将液冷散热、NVLink/NVSwitch高速互连、InfiniBand网络、供配电和集群管理软硬件打包为“即插即用”的一体化解决方案。
最新的NVIDIA GB200 NVL72架构中,一个机柜内集成了36颗Grace CPU和72颗Blackwell GPU,形成72-GPU的NVLink高速域,相当于一台单架柜的“准Exa级”超级计算机。该方案采用全液冷设计,提供130TB/s的GPU间通信带宽,将过去需要多个机架级别的算力浓缩到一个机柜,大幅降低部署复杂度。
类似的整柜产品还内置了电源分配、控制管理和优化的固件,使客户收到后无需自行调试组装,即可像交付一面“算力之墙”那样快速上线使用。这样的系统交付能力是英伟达“软硬一体”战略的重要组成部分:它既确保了芯片性能在系统层面的充分发挥,又让客户省去了自行集成的麻烦,进一步巩固了供应商锁定。
相比之下,博通等竞争者虽在某些组件上有优势(如以太网交换芯片、NIC网卡等),但要提供类似“交钥匙”的AI超级计算整机柜仍有不小差距。多数定制芯片客户最终还需自行或借助ODM厂商完成系统集成,这无形中增加了采用非标准芯片的难度和时间成本。
3.既有装机量与生态飞轮 :最后,不容忽视的是英伟达已经累积的庞大装机存量和产业生态飞轮 效应。截至目前,全球各大云服务商、研究机构和企业部署的AI GPU节点数以百万计,其中绝大部分是英伟达A100、H100系列GPU。
这些现有算力形成了一个巨大的生态土壤:上百万训练过的模型、无数优化调优的高性能库、遍布学术和工业界的人才技能储备,都围绕英伟达平台而建立。这意味着每一份新增算力需求,自然会倾向于选择与现有环境兼容的方案,以无缝利用已有成果并避免“从头再来”。大型模型团队在Nvidia架构上积累的最佳实践经验,使得他们在扩容时边际成本最低的选择仍是追加更多GPU 。
反之,若改用全新架构,不仅前期成果难以复用,人才也需要重新培养,风险与成本都难以接受。因此,英伟达在AI领域已形成正反馈循环 :装机越多→生态越完善→新增应用更愿意采用→进一步扩大装机。新玩家想打破这一循环,需要的不仅是性能超越,更要提供迁移路径、生态支持等全套方案,否则很容易陷入“性能很好却无人用”的困境。
OpenAI自研芯片由于仅内部使用、生态封闭 ,其影响力被锁定在OpenAI自身,对整个行业的生态格局几乎不产生外溢效应。这更加凸显了这样一个方法论判断:在AI算力之争中,孤立的硬件性能并非决定性因素,生态体系的总和才是真正的胜负手 。
四、对于英伟达的影响
在中短期(1-3年)内,英伟达凭借“芯片+系统+生态”的复合垄断优势,地位依然稳固难撼。OpenAI携手博通造芯的动作,更多是着眼于其自身长期算力保障和成本优化,对英伟达当前商业版图的冲击相当有限。
首先,时间维度上,OpenAI定制芯片最快要到2026年才能大规模供货,在此之前OpenAI仍然需要依赖英伟达GPU支撑业务运营(据报道OpenAI目前仍是英伟达主要客户之一)。即便2026年后OpenAI部分工作负载转移到自研芯片,英伟达届时很可能已推出更新一代的GPU(如Rubin架构)以及更完善的软件优化,继续保持性能领先。其次,体量维度上,OpenAI一家削减对英伟达采购,并不足以撼动英伟达盘踞的80-90% AI加速器市场份额 。
目前云计算四巨头(谷歌、亚马逊、微软、Meta)尽管各自都有自研AI芯片计划,但据统计它们依然贡献了英伟达相当比例的收入。例如谷歌开发TPU同时,每年仍采购大量英伟达GPU以满足多样化的AI任务需求;微软即便投资OpenAI芯片,旗下Azure云和内部产品也离不开英伟达GPU的支撑。
再者,OpenAI芯片的用途局限 也决定了其对英伟达的替代效应有限——据传这款芯片主要用于AI推理加速(即模型部署阶段),而在大模型训练这一高端市场,英伟达H100/GH200等GPU依旧是首选。而英伟达近年来在软硬件协同上发力,使其GPU不仅在训练,在推理性能和能效上也快速提升(如H100 NVL专门针对大模型推理进行了优化)。因此OpenAI新芯片能否在性能或成本上明显胜出,还有待观察。
综合来看,OpenAI押注自研芯片更大的意义在战略层面——为长远的算力自主权和成本控制埋下伏笔,而非立即改变市场格局。英伟达短期内坐拥全面优势:一方面数据中心GPU业务增长强劲(2025年Q3英伟达数据中心营收同比大增112%,达308亿美元),手握订单饱满;另一方面其生态护城河使客户粘性空前提高,新方案很难迅速撬走存量客户。
在可以预见的1-3年内,英伟达的地位更像是“AI算力界的主机厂”,从芯片到整机全盘输出,形成事实标准。正如行业评论所言:“硬件创新远不足以挑战英伟达,新进入者必须构建完整的软件生态才能让用户无缝过渡”。
目前看,无论OpenAI-博通,还是谷歌、亚马逊的芯片计划,短期都无法提供这样的横向通用生态。因此英伟达的领先优势在未来数年仍将持续。或许真正的竞局变化,要到这些定制芯片迭代数代、并在更广泛社区站稳脚跟之后。然而在此之前,英伟达凭借其系统级交付能力和开发者牢靠锁定,依然是AI算力领域当之无愧的王者。OpenAI造“芯”航船已经扬帆,但英伟达这艘航空母舰凭借深厚的生态底蕴,暂时依旧稳航在前。