国产AI芯片的六路大军:谁能杀出重围?
一、AI算力的“围城”
国产AI芯片的故事,往往从“追赶英伟达”开始。但老实说,这句话已经被说烂了。
英伟达是山顶的珠峰,仰望它的公司太多,真正能爬上去的几乎没有。
更现实的比喻是:在竞争激烈的战场上,中国已经列阵成形的六路大军——寒武纪、华为昇腾、海光、沐曦、摩尔线程、燧原科技。每一支队伍都声称能攻城拔寨,但武器不一样,打法也各异。有人练刀,有人修枪,有人直接搬石头砸。问题是:哪一路能冲到城墙下,哪一路会半途崩盘?
今天我们就不讲空洞的“芯片自主”,也不再复述“美国封锁”的老调,而是把这六家公司放在同一张桌子上,拆开它们的技术路线,看清谁走的是大道,谁还在小路上打转。
二、先扫盲:AI芯片到底有几种?
别急着看公司,先搞懂战场。AI芯片主要分几类:
- CPU(中央处理器,万能但慢) :像通才,样样都能干,但不够极致。
- GPU(图形处理器,专长并行计算) :像一群壮汉一起搬砖,干重复活最在行。除了传统做图形渲染的GPU,还有面向AI训练和高性能计算(HPC)的GPGPU(通用GPU) ,典型代表是英伟达A100/H100,以及海光的DCU(深度计算单元)。
- NPU(神经网络处理器,专做AI运算) :专职工人,流水线式地干深度学习任务。
- ASIC(专用集成电路,为特定任务定制) :像专门造螺丝的机器,效率极高但不能换活。
- FPGA(现场可编程门阵列,可灵活改造电路) :介于CPU和ASIC之间,灵活但功耗和效率低于ASIC。
这几类架构背后,其实代表了两条主线的赛跑:GPU的通用性 与ASIC的专用化 。GPU靠并行计算与生态称王,预计2025年仍将占据全球AI芯片市场约一半份额;ASIC凭借能效和成本优势,在特定场景“以快打慢”,出货量正在快速上升。未来,两者大概率长期共存。FPGA和NPU则在边缘、试验和特定领域承担补位角色。
需求侧也决定了竞争格局:数据中心是主战场,云厂商构建超大规模集群,训练和推理撑起了半壁江山;边缘和物联网快速增长,安防摄像头、工业节点、智能音箱都在嵌入AI芯片;智能汽车成为新增长极,车规级AI芯片算力正从百TOPS向千TOPS迈进;而在智能手机和终端设备里,几乎所有旗舰SoC都已经内置NPU。可以说,云端是骨架,边缘和终端是毛细血管 ,共同把AI算力需求推向高潮。
三、六家公司逐一拆解
1. 寒武纪(Cambricon)
寒武纪是国产AI芯片的“第一个名牌”,早年以面向终端的NPU起家,近年重心转向数据中心。
技术路线 :NPU。自研指令集(芯片执行“语言”)并打造国产生态,长期目标对标CUDA(英伟达软件生态)。
优势 :技术底子硬,已切入大模型与互联网头部客户,2025H1营收与利润转正,规模效应初显。
问题 :客户集中与可持续性仍需验证,生态与CUDA体系差距明显。
一句话点评 :从“学霸论文”走向“现金流证明”的关键一年,但还需要更分散的客户结构和更厚的软件栈来把拐点焊死。
2. 华为昇腾(Ascend)
昇腾是目前体系化上最接近英伟达的中国选手。它不是单独一颗芯片,而是整个体系:昇腾芯片+ CANN(算子库)+ MindSpore(深度学习框架)。
技术路线 :NPU。昇腾310、910覆盖从边缘到数据中心。
优势 :生态完备,“软硬云端一体”。政企/科研/国产大模型厂商深度绑定,国内加速卡份额居前。
问题 :受制裁与制程约束,5nm以下先进产能紧张,算力与Blackwell世代差距存在。
一句话点评 :正规军打法,长期主义堡垒,但要持续用产品、生态、产能 三件套压缩差距。
3. 海光(Hygon)
海光是“补位型”角色。最初通过与AMD合资获得Zen架构授权推出国产x86 CPU,后续也布局GPU。
技术路线 :CPU + DCU。海光把自家GPU产品称为DCU,本质上属于GPGPU,主要面向AI训练和高性能计算(HPC)等计算密集型任务,而非图形渲染。
优势 :产业链根基稳,在国产服务器里有份额;CPU短期仍是刚需。
问题 :授权升级受限,自主性与路线迭代空间受约束;DCU虽切入AI训练市场,但生态和性能尚需验证。
一句话点评 :价值在于补位与兜底 ,并不承担“改变格局”的预期。
4. 沐曦(Metax)
新锐,明确冲GPU通用算力。
技术路线 :GPU,兼顾图形与AI,强调对生态与框架的兼容。
优势 :方向对路;已进入部分行业客户测试与小规模供货。
问题 :生态与驱动是硬骨头,追赶十余年积累并非一年两年能补齐。
一句话点评 :路线正确、姿势标准,后劲取决于生态与交付。
5. 摩尔线程(Moore Threads)
团队豪华、资源雄厚。
技术路线 :全功能GPU,同时盯图形渲染与AI算力。
优势 :团队强、融资足,能快速推出可用GPU。
问题 :双赛道摊薄资源;首代产品在性能/驱动/生态上尚难支撑大规模商用。
一句话点评 :野心是重建国产GPU全生态,但眼下命题是先活下来并把口碑打实。
6. 燧原科技(Iluvatar CoreX)
打法直接:主攻训练算力。
技术路线 :GPU类AI加速卡,对标A100/H100。
优势 :聚焦单点、客户清晰,便于与头部大模型公司深度绑定。
问题 :Blackwell时代已至,性能与生态差距仍需追;开发者生态薄弱。
一句话点评 :刺客型选手,要速度,更要生态粘性。
四、横向对比:一张表看懂六路大军
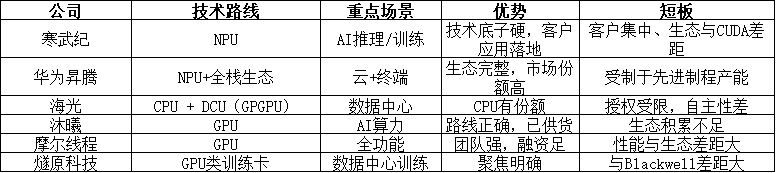
昇腾是正规军,寒武纪是学霸,海光是补位工,沐曦和摩尔线程是新锐挑战者,燧原是冷静的狙击手。
在横向对比之上,还要看供给与政策变量 :先进制程、HBM、CoWoS等关键环节偏紧,谁能锁定产能谁就能先兑现;国内产业基金与地方扶持能加速生态,但也要警惕“资本热于工程冷”;美国出口管制在收紧高端GPU供应的同时,也给了ASIC/NPU国产替代的窗口。真正能跑出来的公司,必须同时穿越这三道门:产能、交付、客户稳定性 。
五、趋势与判断:谁能突围?
短期:华为昇腾最稳,它背靠华为生态,有资金、有客户,能在国产大模型里大规模落地。海光也能凭借CPU补位继续存在。
中期:寒武纪受限于产能爬坡,需求旺盛但交付是关键;燧原若能补齐性能与生态,也有望形成自己的护城河。
长期:大规模通用算力的竞争,仍以GPU及其生态为决定性。沐曦和摩尔线程能否建立属于中国的CUDA生态,将决定它们是昙花一现,还是国产算力的中流砥柱。同时,ASIC/NPU在细分场景也可能胜出。
对投资者来说,筛选逻辑应该是“三维三防线”:
三维筛选 :性能—能效—成本曲线;生态锁定度(算子库、框架、驱动、开发者);交付把控力(产能、HBM绑定、客户结构)。
三条防线 :防泡沫(收入与现金流质量)、防误配(技术路线是否对接主流模型/场景)、防黑天鹅(制程/封装/政策环节出意外)。
一句话:买“工程能力”和“生态势能”,别买PPT跑分。
风险也不能忽视:模型范式迭代快,可能改写“最优架构”;CUDA的生态锁定效应极强,短期内难撼动;云厂商资本开支节奏与宏观经济周期,会让需求波动大;而在股市层面,兑现节奏就是股价节奏,“超预期转不及预期”的切换会被无限放大。
六、结语:胜负在未来
国产AI芯片这条路,注定是长跑。今天的热闹,不代表明天的胜利。
寒武纪的技术、昇腾的体系、海光的补位、沐曦和摩尔线程的野心、燧原的专注,最终能不能撑起一片天,还要看生态和市场的检验。
资本市场最爱讲故事,但芯片不是故事,是血淋淋的工业体系。要烧钱,要时间,要耐心。最后的赢家,不一定是最会喊口号的,而是最能活下来的。
别忘了:AI芯片的胜负,不在今天的发布会,而在未来的存亡录。投资者要盯紧的,是谁能持续迭代、谁能真正落地。