GPT-5不再“胡说”?AI幻觉率下降背后的真相
在人工智能的世界里,“幻觉”是一个令人头疼的词。它指的是模型生成虚假、不准确甚至荒谬内容的现象。过去几年,随着大语言模型(LLM)在各类应用中广泛落地,幻觉问题成为制约其可信度的核心障碍之一。
但最近,GPT-5的表现让人眼前一亮。根据OpenAI最新发布的论文及多篇技术解读文章,GPT-5的幻觉率显著下降。
OpenAI给出的数据显示,GPT-5出现事实错误的概率比 GPT-4o 低约 45%,比 OpenAI o3 低约 80%。
是什么让幻觉概率下降?这又显现出GPT未来怎样的进化路径呢?
幻觉为何频发?AI的“自信错觉”
幻觉是不可避免的,这个结论并不新鲜。可以说,“幻觉”是一种在LLM统计学习本质下必然会产生的、可预测的副产品。
早在GPT-3时代,用户就频频反馈模型“胡说八道”,生成内容看似合理,实则漏洞百出。其根源可归结为以下几点:
语言模型的预测机制 :LLM本质上是概率预测器,它根据上下文预测下一个词。若训练数据中存在偏差或缺失,模型可能“编造”信息以填补空白。
缺乏事实验证能力 :传统模型无法实时访问数据库或验证事实,导致生成内容无法自我校验。
训练数据的混杂性 :互联网上的数据质量参差不齐,模型在学习过程中不可避免地吸收了错误信息。
评估体系的滞后 :早期模型评估更关注语言流畅度,而非事实准确性,导致幻觉问题被忽视。
这些因素共同作用,使得AI在面对复杂任务时容易“自信满满地胡说八道”。
GPT-5的“去幻觉”之路:七大技术事实揭示真相
GPT-5的幻觉率下降并非偶然,而是技术团队在训练方法、评估机制和模型架构上的系统性优化。以下是从多篇文章中提炼出的九个关键事实:
引入多阶段训练机制 :GPT-5采用分阶段训练策略,先进行基础语言建模,再进行强化学习微调,显著提升模型对事实的敏感度。
使用高质量数据集 :训练数据经过严格筛选,剔除低质量网页、虚假信息和重复内容,确保模型学习的基础更为扎实。
加入事实验证模块 :模型在生成内容时引入事实校验机制,能在一定程度上自我纠错。
引入人类反馈机制 :大量人类标注者参与训练过程,对模型输出进行评分,帮助模型理解“什么是正确的”。
构建多维评估体系 :不仅评估语言流畅度,还引入事实准确性、逻辑一致性等维度,全面衡量模型表现。
提升模型参数规模 :GPT-5参数量进一步扩大,使其具备更强的知识表达和推理能力。
采用对比学习策略 :模型在训练中学习“正确与错误”的差异,增强辨别虚假信息的能力。
这些技术手段共同作用,使GPT-5在多个评估任务中幻觉率显著下降,部分任务甚至优于人类平均水平。
AI幻觉率下降的深层逻辑:从“语言模型”到“知识模型”
GPT-5的进化不仅是参数规模的扩大,更是模型认知方式的转变。
过去的语言模型更像“语言模仿者”,擅长生成流畅文本,但缺乏事实判断力。而GPT-5开始向“知识模型”靠拢,具备一定的事实理解和逻辑推理能力。
这种转变背后,是训练目标的变化——从“生成合理语言”转向“生成真实语言”。这不仅需要更好的数据和算法,也需要更复杂的评估体系。
此外,GPT-5在训练中引入了“对比学习”和“人类反馈”,让模型学会“什么是错的”,而不仅仅是“什么是对的”。这种负反馈机制,是幻觉率下降的关键所在。
主流AI产品幻觉率对比:GPT-4领先,但还不够好
虽然GPT-5在技术上取得突破,但幻觉问题并未彻底解决。不同AI产品在幻觉控制上的表现仍存在显著差异。
以下是某媒体列出的主流AI产品幻觉率对比(单位:任务幻觉率百分比,不包括GPT-5,GPT-5幻觉率大约比GPT-4低45%):
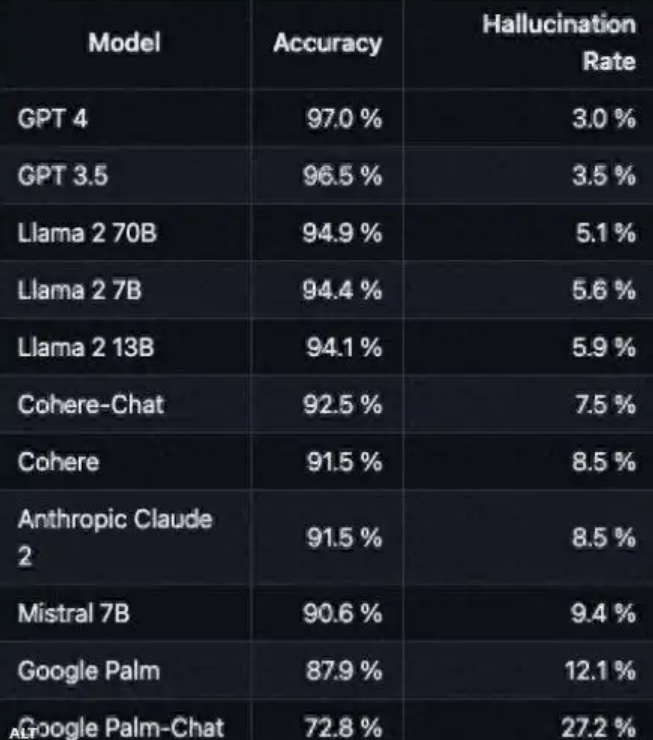
可以看出,GPT系列的幻觉率远低于其他主流模型。这得益于其更复杂的训练机制和更严格的评估体系。
但值得注意的是,幻觉率并非唯一指标。模型的可解释性、响应速度、语言覆盖度等也影响其实际应用效果。
模型仍可能在特定任务中生成错误信息,尤其是在数据稀缺或语境复杂的场景下。“尽信书不如无书”这句话在大模型领域依然适用。
未来,AI要真正成为可信赖的助手,还需在事实验证、知识融合、逻辑推理等方面持续突破。