FP8狂潮来袭:谁能吃下这场“效率红利”?
一、算力内卷的尽头是场“减法革命”
过去几年,AI芯片的套路只有一个字:“堆”。晶体管、功耗、频率,恨不得全部拉满,好像GPU的任务就是比谁更能烧钱烧电。
但你再强,终究跑不过电表。今天,算力已经卷到天花板,再往上堆,就不是实力比拼,而是比谁家电厂能跟得上。
如今,一个只有8位的小数格式——FP8(8-bit Floating Point,即8位浮点数,一种AI低精度计算格式)——登台了。
它不追求算力有多么夸张,而是教AI如何精打细算,把芯片上的每个电子都“薅到秃头”。
别小看这8位数的小东西,它掀起的不是算力竞赛,而是“省力竞赛”。
二、FP8是什么?
FP8,是一种专门为深度学习量身定制的8位浮点数。说白了,就是数字的极简主义,用更少的位数表达更多的意义。
过去芯片用FP32(32位浮点数,主流高精度计算格式),就像学术论文,精确又冗长;
FP8则像是AI芯片圈的“网络文学”:虽谈不上精致,却直击人心,让机器跑得又快又省。
它主要有两种规格:
E4M3 (1位符号+4位指数+3位尾数):专攻推理场景;
E5M2 (1位符号+5位指数+2位尾数):专攻训练场景。
现在全球两大算力巨头英伟达和AMD纷纷入场,形成两套主流格式。这场“8位数的军备竞赛”,搅动了从AI训练芯片到数据中心GPU的整个产业链。
在典型公开实现中,与FP32相比,FP8可将参数存储与带宽需求显著下降(常见量级为50%–75%),在相同功耗下吞吐有望提升至约2倍量级。具体幅度取决于架构、模型与量化策略。
FP8真正干的事,是让AI从高高在上的论文,变成你家门口的包子铺:便宜、好用、管饱。
三、FP8的价值不在强多少,而在省多少
现在,能量与带宽成为算力的瓶颈之一FP8的作用,就是在“算力、能耗、存储”这三者之间重新平衡。
FP8不是“最强算力”,而是“最优性价比”。
当位宽从FP32降到FP8,每次数据传输、显存占用、计算量直接腰斩,算力没变强,却省了一大半的成本。
来看一组数据(典型量级):
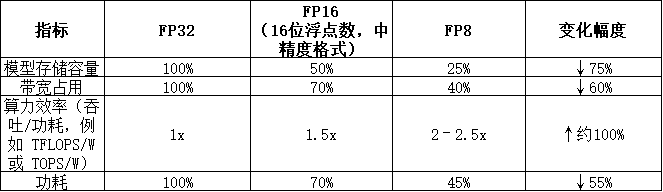
注:以上为典型公开实现的量级示例,实际幅度随架构、模型与量化/校准策略而变化。
AI的真正成本,不在芯片,而在电费。
FP8算的不是AI的面子,而是AI的里子,是实实在在的利润空间。
在AI行业,省钱的技术永远比烧钱的技术活得更久。
四、全球FP8竞争格局
说白了,FP8就是场“省钱内卷”,谁都逃不掉。
美国这边:英伟达H100、AMD MI300、Intel Gaudi3(英特尔AI加速芯片),个个都是FP8高手。他们不是因为FP8最强,而是因为大模型玩不起了,必须精打细算过日子。
中国这边:寒武纪、华为昇腾(Ascend,国产AI芯片系列)、海光信息,能适配FP8的芯片越来越多;华大九天、芯华章、概伦电子,也在为FP8生态补足工具链。
政策支持也到位了,相关算力与基础设施指南对能效和低精度计算提出要求,FP8等低位宽路径与之方向一致。
虽然起步稍晚,但追赶节奏明显加快,差距正在收敛,部分环节已有并跑迹象;在架构实现与生态成熟度上仍有差距,不同环节差异不一。
政策背后还有资本推手——从国产GPU到AI服务器,FP8兼容性与能效表现已被实务性关注,有望成为算力采购评估维度之一。
FP8更像算力世界的“精打细算工具”,让高算力更易被规模化部署。
五、中国FP8落地的“三步曲”
第一阶段(2023–2024)技术卡位期
寒武纪、昇腾完成FP8指令集与架构适配,EDA(电子设计自动化,芯片设计软件)厂商进行仿真验证。
这一阶段主要是“技术准备”,核心任务是模型精度与算力兼容。
第二阶段(2025–2026)商业起步期
大模型推理先行,浪潮信息、中科曙光FP8服务器落地,生态闭环成型。
第三阶段(2026–2028)全面规模化
随着标准与生态逐步统一,FP8有望成为主流方案之一,利润弹性具备释放基础。
现在FP8看着还不起眼,但市场最好的机会从来都是这样:先被低估,然后才被疯抢。
六、FP8产业链完整图谱
1.芯片与架构层
寒武纪、燧原科技、海光信息、华为昇腾、龙芯中科、兆易创新、圣邦微电子、华为海思、紫光展锐、士兰微、华润微、粤芯半导体、中芯国际、华虹集团。
2.设计与制造支撑层(EDA/IP/封测/材料)
华大九天、芯原股份、平头哥、赛昉科技、安谋科技(中国)、Synopsys(新思科技,全球EDA龙头)、Cadence(楷登电子,EDA工具厂商)、Siemens EDA、Ansys、Keysight(是德科技)、通富微电、晶方科技、太极实业、深南电路、弘信电子、生益科技、依顿电子、澜起科技(内存接口/缓冲)。
3.算力与服务器层
浪潮信息、中科曙光、工业富联、紫光股份、新华三、鸿海精密、智微智能、青云科技、优刻得、光环新网。
4.AI应用与软件生态层
智谱AI、百川智能、零一万物、知乎科技、天数智芯、寒武纪(算法优化)、AMD中国、佳都科技(系统集成)。
5.互连与支撑层(通信/散热/科研)
中际旭创、新易盛、兆龙互连、兴森科技、景旺电子、胜宏科技、英维克、中石科技、长盈精密;
科研及创新机构包括:中国科学技术大学、国防科技大学、浪潮研究院、DeepSeek团队、硅基流动科技、迈基诺基因。
FP8并非技术创新这么简单,而是一整条AI产业链的效率升级。
七、投资启示
FP8不是概念股,而是效率股。
上一轮炒AI靠概念、靠堆料,这一轮必须靠技术和效率说话。
芯片公司、服务器公司、EDA工具公司,能同时受益。
但也要冷静看三大风险:标准不统一、算法适配难度高、商业落地节奏慢。
话虽如此,趋势的车轮不会停。
AI模型越大,就越需要FP8式的“精打细算”,最终赢的不是谁算力最大,而是谁账算得最准。
效率红利并非平均分配,能把FP8工程化做到稳定与规模的企业,才可能分享到超额收益。
FP8的出现,也许标志着AI硬件正式进入“效率周期”——从拼性能到拼能效,从算得快到算得值。
它的广泛应用,意味着AI芯片从“野蛮生长”走向“精算时代”。过去十年是堆晶体管、卷制程、拼显存;接下来的十年,是算力密度与能效比的战争。FP8的普及,让AI第一次真正开始讲效率,而不是炫技。
国家层面的算力战略与基础设施投资,将成为决定国产FP8能走多远的关键因素。政策不是风向,而是地基——只有政策兜底、生态协同,国产FP8体系才有机会形成真正的闭环。
随着FP8在AI芯片、数据中心、加速卡领域的渗透加速,中国的AI算力生态正在进入“自循环时代”:芯片能自研、框架能自适、生态能自长。
医疗、自动驾驶、智能制造等算力敏感行业,将率先享受到FP8带来的效率红利。到那时,AI的边界不再是技术瓶颈,而是能源与成本的边界。
AI芯片行业,正在从比“谁更强”,变成比“谁更省”。FP8,这个8位的小数,可能成为整个AI硬件成熟的分水岭——它让AI重新回到理性:
不是更复杂,而是更高效;不是更贵,而是更值。
未来几年,FP8或许会成为衡量AI芯片成熟度的标准语言。
资本市场从来不缺惊天动地的技术,缺的,是能兑现利润的技术。